
티스토리 뷰
본 내용은 aws ec2 ubuntu 서버에서 진행됩니다.
ubuntu 환경에서 크롤링을 진행하려면 몇 가지 설치가 필요합니다. 설치 방법은 아래 링크를 참고해주세요!
https://dvpzeekke.tistory.com/1
AWS EC2 ubuntu에 selenium, chrome, chromedriver 설치하기
본 내용은 aws ec2 ubuntu 서버에서 진행됩니다. selenium 설치하기 selenium을 포함한 다른 패키지들을 설치할 때, pip을 사용합니다. $ sudo apt-get install python-pip 위 명령처럼 pip을 설치해주세요. $ sud..
dvpzeekke.tistory.com
설치가 완료되었다는 가정 하에 시작하겠습니다.
크롤링은 웹페이지에서 데이터를 추출하는 것을 지칭합니다. 그리고 크롤링을 수행하는 소프트웨어를 크롤러라고 부릅니다. 오늘은 네이버 홈페이지에서 오늘의 날짜를 가져오는 크롤러를 만들어보겠습니다.
먼저 앞선 게시물(위 링크 참조)에서 작성한 코드는 다음과 같습니다.
|
1
2
3
4
5
6
7
8
|
from selenium import webdriver
from pyvirtualdisplay import Display
display = Display(visible=0, size=(1024, 768))
path = '/home/ubuntu/chromedriver'
driver = webdriver.Chrome(path)
|
|
이 상태에서 더 필요한 건 네이버 홈페이지의 url과 날짜 데이터의 xpath입니다.
날짜 데이터의 xpath를 가져오는 방법은 매우 간단합니다.

위 캡처 화면과 같이 크롬 브라우저에서 네이버 홈페이지 접속 후 '날짜 텍스트 마우스 우클릭 > 검사'로 이동하시면 우측에 html 코드가 등장합니다. 그리고 html에서 오늘의 날짜가 적힌 텍스트를 보실 수 있습니다.
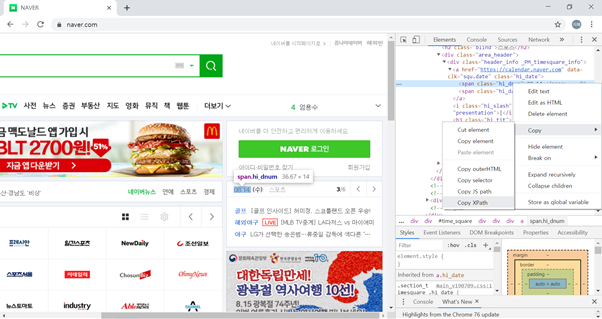
위 화면과 같이 'html 안의 날짜 텍스트 마우스 우클릭 > Copy > Copy XPath' 순으로 클릭해주세요. 그리고 나서 다시 코드를 작성해봅시다.
|
1
2
3
4
5
6
7
8
|
url = "https://www.naver.com/"
xpath = "//*[@id=\"time_square\"]/div/div[1]/div[1]/a/span[1]"
date = driver.find_element_by_xpath(xpath).text
print(date)
|
|
앞서 작성했던 코드 밑에 위 코드를 삽입합니다.
먼저 변수 url이 지칭하는 것은 네이버 홈페이지의 url이고 크롬드라이버가 해당 url로 접속하게 만듭니다.
변수 xpath엔 직전에 복사한 xpath를 할당합니다. 주의할 점은 복사한 xpath 내에 큰따옴표가 존재한다면 해당 큰따옴표 앞에 \(백슬래쉬)를 삽입해야 합니다.
date 변수는 xpath가 가리키는 element를 찾아 그 값을 저장합니다.
date 변수가 가진 값을 print 해보면 오늘의 날짜가 출력됨을 확인할 수 있습니다.
'Dev.Cloud > AWS' 카테고리의 다른 글
| AWS EC2 ubuntu 서버에서 python 버전 변경하기 (0) | 2019.08.15 |
|---|---|
| AWS EC2 ubuntu에 selenium, chrome, chromedriver 설치하기 (3) | 2019.08.13 |
- Total
- Today
- Yesterday
- ios
- SummerCoding
- 스위프트
- c++
- 서머코딩
- Collection
- 구슬탈출
- 자료구조
- 호제법
- 이진트리
- 백준
- Xcode
- 컬렉션
- aws
- 삼성역량테스트
- 알고리즘
- datastructure
- 깊이우선탐색
- BFS
- ec2
- 시뮬레이션
- algorithm
- dp
- 프로그래머스
- 코딩테스트
- dfs
- Programmers
- Swift
- isempty
- count
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |